
�����������҇��������2005��90�����й�˾�����о��������䱻STǰһ��Ľ��攵������һ��ؔ��ָ���wϵ������Logistic �ؚw��BP�W�j��������ؔ��Σ�C�A��ģ�ͣ� �M���ˌ��C�о���
����һ���P�ߌ�ؔ��Σ�C�Ľ綨
������ν綨ؔ��Σ�C���M��ؔ���A���о����]����Ҫ���}��������о�����I���Ʈa��������Ʈa��Ո���О�����_����I�M��ؔ��Σ�C�Ę�־��Altman ��1968��ָ��ؔ��Σ�C��4�N��ͣ����Iʧ�����o�����������`�s���Ʈa��Deakin ��1972���J��ؔ��Σ�C��˾��ָ�ѽ��Ʈa���o����߀���ն��ѽ��M������Ĺ�˾��ROSS���ˣ�1999���J��ɏ�4�����涨�x��I��ؔ��Σ�C����Iʧ���������Ʈa�����g�Ʈa����Ӌ�Ʈa�������҇��Cȯ�Ј��l��������죬ȱ����ȫ�����ЙC�ƣ������Y��һֱ�ܵ��C�O���ć�����ƣ��������ʹ�I����ġ����YԴ�����й�˾���ֿɟᣬ����̎���Ʈa��߅����Ҳ������ȫ���ա��ʶ����Y���҇��Č��H��r���P�߰ѹ�˾���e̎����ST����������ؔ�������Ę�־��ST�ƶ��nj�����r�����������й�˾������Ʊ�����e̎�����P�����о��Ќ�ؔ��Σ�C�_�н綨�鹫˾ؔ�ՠ�r�����������e̎������
���������������īI�C��
����Ŀǰ���о�ؔ���A����ģ����Ҫ�����������ģ�ͣ���׃��ģ�͡���׃���yӋ����ģ�ͺ��˹��W�jģ�͡�
������һ����׃��ģ��
����ԓģ���о������������֥�Ӹ��W����WilliamBeaver ��1966��������^�����Ć�׃��ģʽ������79��ʧ����I����ͬ������ͬ��Ҏģ�ɹ���I��ӱ���ͨ�^�о����eؔ�ձ����L���߄��A�y��I���RΣ�C��r���҇��W����o��1999����1998���27��ST��27�ҷ�ST��˾������1995��1997���ؔ�Ո�픵���M���ˆ�׃��������������ӱ��ʺ�ؓ�������`������ͣ������r���R�t�x��2001����70��ST��70�ҷ�ST���й�˾��ӱ������Æ�׃�������о�ؔ���������Fǰ������@���˾21��ؔ��ָ�˸���IJ�����_����6���A�yָ�ˡ�
������������׃���yӋ����ģ��
������׃���yӋ����ģ��ͬ��׃��ģ����ȣ���ȫ��ط�ӳ����I��ؔ�ՠ�r�����ڽ�ģʹ�õĽyӋ������ͬ���ַ֞��Ԫ�ؚw����ģ�͡���Ԫ�Єe����ģ�͡����ɷַ���ģ�ͺ�Logisitic�ؚwģ�͡������W��Edward Altman�������Ȍ���Ԫ�����Єe��������ؔ���A���I���_���˶�׃���A��ģ�͵��Ⱥӣ����Z��scoreģ�ͣ����ᣨ2000���xȡ�������14���ИI120�����й�˾��ӱ����ă���������ӯ���������Y���Y����r�͠I�\��r4������15�����Pؔ�ձ����кY�x��4��׃�������˶�������ж�ģ�ͣ������A��1996��������F�֔�ģ�͡�����Logisitic�ؚwģ���ѽ������˂��ĸ߶��Pע��
���������� �˹��W�jģ��
�����˹��W�j��ANN���İlչʼ��20���o40����������ô����Ǿ��Բ���̎���Pϵ��ģ�M��������X��Ԫ���\���������^�õ�ģʽ�R�e���W����Ӗ�������e�������˷��˂��y�yӋ�����ľ��ޡ�M.Odom��1990��������˹��W�j������ؔ��Σ�C�A�y�о�����Rumelhart��McClelland��1986�������һ�N����ǰ���W�������BP�W�j�������m����ģ�Mݔ�롢ݔ���Ľ����Pϵ�����Ҿ��Пo���[���ӹ��c������BP�W�j���Ԍ��F�����ݔ�뵽ݔ���ķǾ���ӳ�䣬ͬ�rҲ�ǽ���푪����V��������ANNģ�ͣ�Lapedes��Fayber��1987���״��\���W�jģ�͌��y�������L�U�M�����A�y�ͷ�����Trippi��Turban��1992���������y��ؔ��Σ�C�M���˷������҇��W�ߗ����2001���xȡ15��ؔ��ָ�ˣ��\��BP�W�j���������˹��y���M�������u�r���A��ϵ�y��
�����������C�о�
�����P����Ҫ����Logisitic�ؚwģ�ͺ�BP�W�jģ����Փ���Ѽ����й�˾��ؔ�Ք�����������ͬ�Č��Cģ���M�б��^������ؔ���A����Ч����
������һ���о��ӱ����OӋ
�����P�ߌ��҇����й�˾�е�ST��˾�綨�顰ؔ��ʧ�������xȡ��2005��������е�30��ST��˾��ͬ�ИI���Ҏģ��30�ҷ�ST��˾�����Ӌ�ӱ��M�������xȡͬ�r�ڵ�30��ST��˾�ͷ�ST��˾����yԇ�ӱ��M����Ӌ�ӱ��M�Ĕ������ژ����A��ģ�ͣ����yԇ�ӱ��M���ڙz��A��ģ�͵���Ч�̶ȡ��b���о�����Ҫ�����xȡ��ؔ��ָ�˔�����ST��˾�������e̎��ǰһ�꣨2004����������ӱ���˾��ؔ�Ք�����Ҫ���Ծ���Ӎ�Wվ���Ї����й�˾��Ӎ�Wվ�yӋ���b��
����������ؔ��ָ���wϵ���x��
����ؔ�ձ��ʵ��xȡ�ǘ���ؔ��Σ�C�A��ģ�͘O����Ҫ��һ�����x���ǡ���c���Pϵ��ؔ��Σ�C�A��ģ�͵���Ч�ԡ��P�߲��ö��Է����Ͷ���������Y�ϵķ����� ���b������W�ߵČ��C�о��ɹ����Y���҇����й�˾�Č��H��r�� ����I���Ј��rֵָ�ˡ�ӯ���������������������I���������L�������Y���Y����6�����棬 �ṩ��17�����xؔ��ָ�ˣ������о�ģ����ʹ�õij�ʼ׃�������1��ʾ��
��1 ���xؔ���A��ָ��
| �Ј��rֵָ�ˡ� | ӯ�������� | ���������� | ���I������ | ���L������ | �Y���Y���� |
| ÿ������ ÿ�Ƀ��Y�a�� |
���Y�a����� ���Y�a������ ���I�I�������� �N��ë���� �N�ۃ����ʡ� |
���ӱ��� �لӱ��ʡ� |
���Y�a���D�� �����~�����D�� �ɖ|�������D�� ��؛���D�ʡ� |
���Y�a���L�� ���I�I�� �������L�ʡ� |
�Y�aؓ���� �ɖ|������ʡ� |
����Ȼ����ģ���а�����˶��ָ���Dz������ģ�ͬ�r����ؔ��ָ��֮�g�����P�Ա��^�����Y���e�C���s������ڽ���ģ��ǰ�б�Ҫ����ʼ׃���M�кY�x��ST��˾�ͷ�ST��˾֮�g��ԓ�����@����e���M���A��ģ�͵�׃����������Ч���@���^�eST��˾�ͷ�ST��˾���@�����x׃���ı�Ҫ�l�������ԹP�߲��ýyӋ�������е��@���ԙz����T�z���A��ָ���M�е�һ�κY�x��ʹ��SPSS�yӋ����ܛ������ؔ��Σ�C��I��̎��ǰһ�꣨2004���Ĕ����M���@���ԙz��T�z�Y�����Կ������xȡ�@����ˮƽ��0.05���ڂ��x��17��ؔ���A��ָ���У� ���Y�a����ʣ�X1�������Y�a�����ʣ�X2�������ӱ��ʣ�X3�����لӱ��ʣ�X4�����Y�aؓ���ʣ�X5�����ɖ|������ʣ�X6�������Y�a���D�ʣ�X7�������Y�a���L�ʣ�X8����ÿ�����棨X9����ÿ�Ƀ��Y�a��X10�����pβ�z���@�����ʾ�С��0.05��ͨ�^���@���ԙz�f���@Щָ��׃����ST��˾�ͷ�ST��˾֮�g�����@����ģ�����xȡ�@10��׃���M���A�yģ�͡�
����������Logistic�ؚw����ģ��
������60�ҹ�Ӌ�ӱ�ؔ��Σ�C�l��ǰһ��Ĕ�������A��ʹ�úY�x��10��ָ�˞���׃��������Logistic�ؚw����ģ�ͣ��\��SPSSܛ�������@��ģ�͵�ϵ�������P����Ҋ��2.
��2 ��Ӌ�ӱ�Logistic�ؚwģ�ͅ�����
| ���� | B�� | S.E.�� | Wald�� | df�� | Sig.�� | Exp��B���� | |
| Step 1��a���� | ÿ�Ƀ��Y�a�� | 1.779�� | .487�� | 13.348�� | 1�� | .000�� | 5.921�� |
| ���� | Constant�� | ��2.326�� | .723�� | 10.353�� | 1�� | .001�� | .098�� |
| Step 2��b���� | ���Y�a���D�ʡ� | .051�� | .024�� | 4.368�� | 1�� | .037�� | 1.052�� |
| ���� | ÿ�Ƀ��Y�a�� | 1.674�� | .560�� | 8.922�� | 1�� | .003�� | 5.333�� |
| ���� | Constant�� | ��2.496�� | .902�� | 7.664�� | 1�� | .006�� | .082�� |
����a Variable��s�� entered on step 1��ÿ�Ƀ��Y�a b Variable��s�� entered on step 2�����Y�a���D��
����ע��B���A��׃���Ļؚwϵ����S.E. ��ؚwϵ���Ę˜��`�Wald�Ǚz�ƫ�ؚwϵ���ĽyӋӯ��df�����ɶȣ�Sig.���@��ˮƽ��
�����ı��п��Կ�����X7��X10׃�����@��ˮƽ��С��0.05���f���A�y�����^�����F����Logistic�ؚwģ�ͣ��䷽�̱�ʾ�飺 Logit��Y��=Ln��P/1��P��=��2.496 + 0.051X7+1.674X10.
��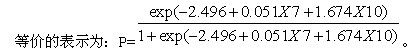
����P��Y=1��������˾�l��ؔ��Σ�C�ĸ��ʣ� P��Y=0��������˾���l��ؔ��Σ�C�ĸ��ʣ���˹P����P=0.5������Єe�c��������ʹ�A��ģ���ڌ��H���и��õ��A�yЧ������P����0.5�r���Єe��ST��˾����ֵԽ����ԓ��˾δ��һ��Ȱl��ؔ��Σ�C�Ŀ�����Խ��PС��0.5�r���Єe���ST��˾����ֵԽС������ԓ��˾ؔ�ՠ�rԽ��ȫ����P����0.5�r���f��ԓ��˾��ؔ�ՠ�r��̫���@����Ҳ�Єe��ST��˾��
�������ģ�BP�W�jģ��
�����P�߲�������BP�W�j����ݔ��ӡ��[���ӡ�ݔ���ӽM�ɡ�ݔ������[�����Լ��[������ݔ���ӵĂ�ݔ�������x�÷Ǿ���S ��Sigmoid �������@���㷨�ČW���^��������ͷ�������^�̽M�ɡ�
�����\��ܛ��Matlab 6.5�� ������10��16��1������BP�W�j�����xȡ��60��Ӗ���ӱ���30���yԇ�ӱ��M�Ќ����⣬����ݔ�����B�m׃����ݔ���Dz������xɢ������ Ӗ����yԇǰʹ��Matlab��Premnmx�������ӱ��M�Кwһ��̎��������W�j��ݔ�딵����BP�W�j���OӋ����ݔ��ӡ��[���ӡ�ݔ���ӡ����f������Ӗ�������ȾW�j�Y���;W�j�������O�ã����w���ı����о����O�����£�
����1.ݔ��ӣ�ݔ�����Ԫ������ݔ�����Q�����_����10��ݔ�빝�c��
����2.ݔ���ӣ�ݔ������Ԫ�Ă�����ݔ��e�Q�������w�����ģ��W�j��ݔ���Ӷ��x��һ�����c�������й�˾�Č��Hؔ�ՠ�r����Ӗ���ӱ����У��ӱ���ݔ��������T������ST��˾�r��T=1�������ST��˾�r��T=0����
����3.�[���ӣ��P���[���c�����xȡ������δ�ҵ�һ���ܺõĽ���ʽ����ʾ���^�٣���Ӱ푵��W�j����Ч�ԣ��^�࣬�t����������ӾW�jӖ���ĕr�g������ģʽ�R�e��BP�W�j��������������ԅ������¹�ʽ�M���OӋ��n=n1+0.618����n1�� n2�����У�n���[���c����n1��ݔ�빝�c����n2��ݔ�����c�����ɴ˹�ʽ�xȡ�[���ӹ��c����16.�P�߲����[������Ԫ������16����
����4.���f���������f�����ĺÉČ�һ���W�j��Ӗ��Ч�����P��Ҫ�����]��ݔ���ӵ�����ݔ��������0��1�������͜yԇ���P�ߌ�ݔ��ӵ��[���ӵĂ��f�����_�������к���tansig��n����������Ԫ��ݔ�뷶���ģ��� ��+ ��ӳ�䵽��1����1�����[���ӵ�ݔ����֮�g�Ă��f�����_���錦������logsig��n����������Ԫ��ݔ�뷶���ģ��� ��+ ��ӳ�䵽��0�� 1����
����5.�W�j������Ŀ���`��0.001���W�����ʞ�0.01��Ӗ��ѭ�h�Δ�1000�Ρ��W����ͨ����0.01��0.9֮�g��һ����f���W����ԽС��Ӗ���Δ�Խ�࣬ ���W�����^��Ӱ푾W�j�Y���ķ����ԡ��`��ͨ����Ҫ����ݔ��Ҫ������� eԽ�ͣ� �f��Ҫ��ľ���Խ�ߡ�
����6.Ӗ�������������xȡ���ڿ���BP�㷨��Ӗ������trainlm����Matlab6.5�Z�Ծ��̌��Fģ����PC�Ͻ��^75��Ӗ�����ں��_��Ҫ��
�������壩��ͬģ�ͽY�����^
��3 ��ͬģ�͵��Єe�ʴ_�ʱ��^
| ģ�����Q�� | ��Ӌ�ӱ��ʴ_�ʡ� | �yԇ�ӱ��ʴ_�ʡ� | ||||
| �� �w�� | ST�� | ��ST�� | �� �w�� | ST�� | ��ST�� | |
| Logistic�ؚwģ���� | 86.7%�� | 86.7%�� | 86.7%�� | 83.3%�� | 80%�� | 86.7%�� |
| BP�W�jģ�͡� | 99%�� | 98%�� | 100%�� | 90%�� | 93.3%�� | 86.7%�� |
�����������ɷNģ��֮�g���Єe�ʴ_�ʱ��^���������@��������Ӌ�ӱ�����BP�W�j�ЄeЧ������Logisiticģ�ͣ��yԇ�ӱ���������ஔ��
�����ġ��о��YՓ��������
�����P���ڻ������ؔ���A��ģ�ͽ����īI���о��ɹ��Ļ��A�ϣ����҇�����90�����й�˾���о���������Logisitic�ؚwģ�ͺ�BP�W�j�����M���ˌ��C�о���
������һ���о��YՓ����
����1.�҇����й�˾��ؔ��ָ�˰������A�yؔ����������Ϣ������������ù�˾��ؔ�ձ��ʿ����A�y���Ƿ�����ؔ�������������й�˾����ؔ��Σ�C��ǰһ�꣬�P�����x��17��ؔ��ָ����10�������ж����A�yؔ����������Ϣ�������@Щָ�˺��w�˷�ӳ��˾ؔ�ՠ�r�ĸ��������أ��f������ָ���wϵ�Ǻ���ǡ���ġ�2.�Ї��C�O�������й�˾��ST�Ķ��x����Ч�ģ����P���C�������й�˾��ST��K�c��ST��K���@���ą^�e�����ø��N�Єeģ�ͼ��ԅ^�֡�3.�о����õăɷNģ�ͷ����������M�й�˾ؔ�������A�y�о������ж�Ч�����ڲ��
�����������о�������һ���ľ�����
����1.�b�ڔ����ռ������ƣ��P���xȡ�Ķ������й�˾��ؔ�Ք��������m���ڴ�����С��˾��
����2.�P�ߵ��о��������й�˾�挍ؔ��ָ�˞�ǰ����O�ģ������ų�Ŀǰ�҇����й�˾��Ӌ��Ϣʧ��F��Ĵ��ڡ�
����3.���ڷ�ӳ��˾ؔ�ՠ�r��ָ�˺ܶ࣬����©��һЩ��Ҫ�ı��ʣ��ó��ĽY���������ơ�
����4.�P���о��������й�˾�Ľ��攵�����]�п��]��STǰһ���������r���ݱؕ�Ӱ푌��C�Y����

